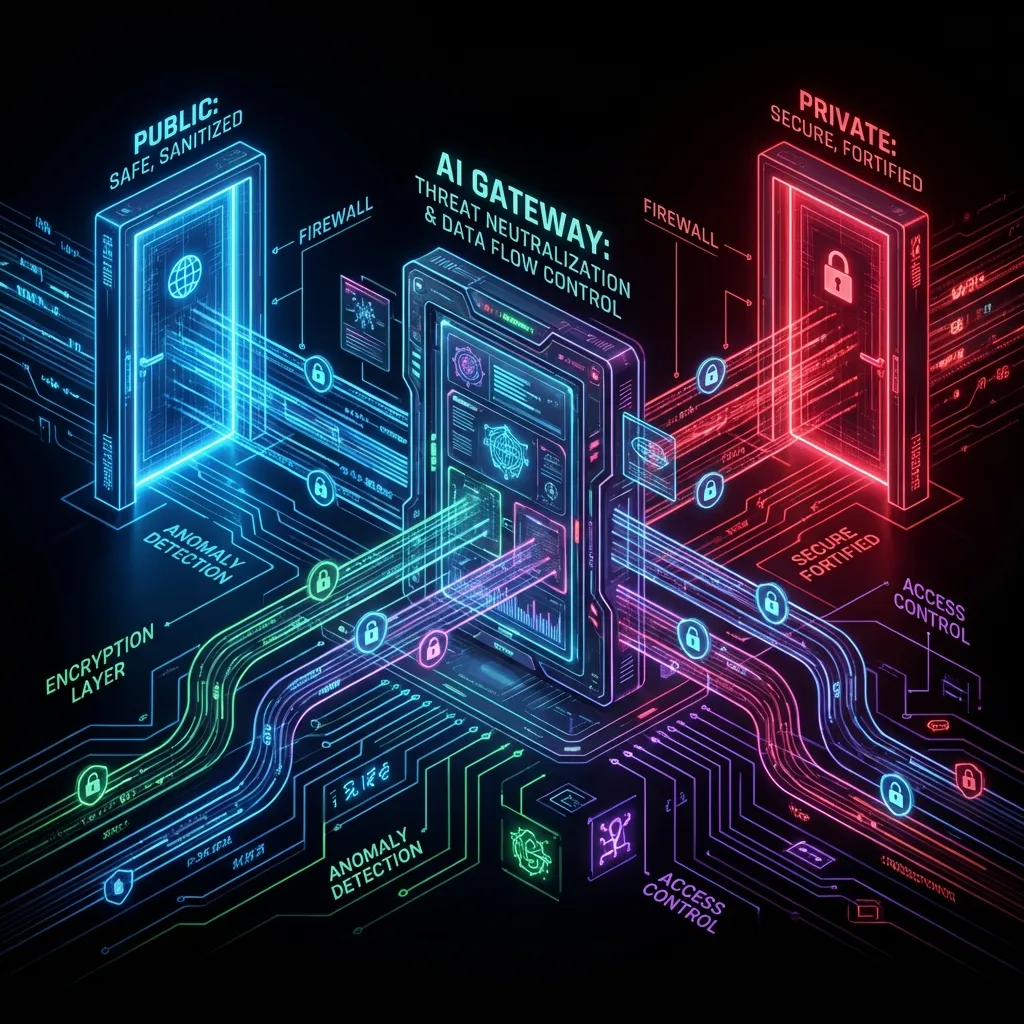
TrustBank wanted AI agents for customers (internet-scale) and AI agents for employees (private-only). The CIO wanted speed. The CISO wanted an audit-proof control story. The solution was a hybrid pattern using dual Azure API Management gateways (APIM) with consistent “AI gateway” policies across both.
TL;DR - Executive Summary
- The Challenge: Scale AI agents for both public customers and private employees while maintaining audit-proof governance
- The Solution: Dual Azure API Management gateways (APIM-External + APIM-Internal) with unified "AI gateway" policies
- The Impact: 60% cost reduction via semantic caching, 100% security coverage, zero-downtime failover, and centralized audit trail
Reading time: 15 minutes | Interactive demos included
What is an AI agent
An AI agent is an application that uses an AI model to understand a goal, decide steps, and call tools (APIs, search, ticketing, databases) to complete the task.
A chatbot mostly talks. An agent can take actions. That is why it needs stronger controls than a normal API.
The Cast

Architecture, standards, trade-offs.

Build, automation, operations.

Identity, data controls, audit.
Delivery strategy, Operating models, Scale-ready roadmaps.

Risk acceptance & operating model.

Decisions, RACI, milestones.
The Strategic Gap
Before governance, teams tend to connect directly to:
- model endpoints (Azure OpenAI / Foundry Models), and
- tool APIs (search, DB, ticketing).
The Problem: Three Predictable Failures
Without centralized governance, direct model access creates:
The CISO requirement was clear:
Controls must be enforced centrally, and we must be able to prove it.

Figure: The Conceptual Flow of a Secure AI Gateway (Source: Azure Samples)
Architecture Decision: Dual APIM
Decision: The "Two Doors" Pattern
For customer-facing agents. Protected by WAF & DDoS at the edge.
For employee agents. Accessible only via VPN/ExpressRoute.
Imagine a pizza restaurant with two entrances: Door 1 (Public) is open to the street for walk-in customers, while Door 2 (Private) is a VIP entrance requiring a keycard. Both doors lead to the same kitchen (Azure OpenAI) and share the same "Jar of Tokens" (quota pool).
Here's the magic—One Rulebook: The Bouncer at Door 1 (APIM-External) and the Bouncer at Door 2 (APIM-Internal) use the exact same rulebook to check IDs and enforce token limits. If the jar goes empty, both bouncers hold up the 429: Not Today sign simultaneously.
Why Two Doors? Door 1 has a WAF shield (security guard at the street entrance), while Door 2 is hidden from the street (only accessible via VPN). But both enforce the same governance—one audit trail, one quota policy, centralized control.
Both gateways implement the AI gateway in APIM capabilities (govern LLM endpoints and MCP/tool APIs).
Reference Diagram
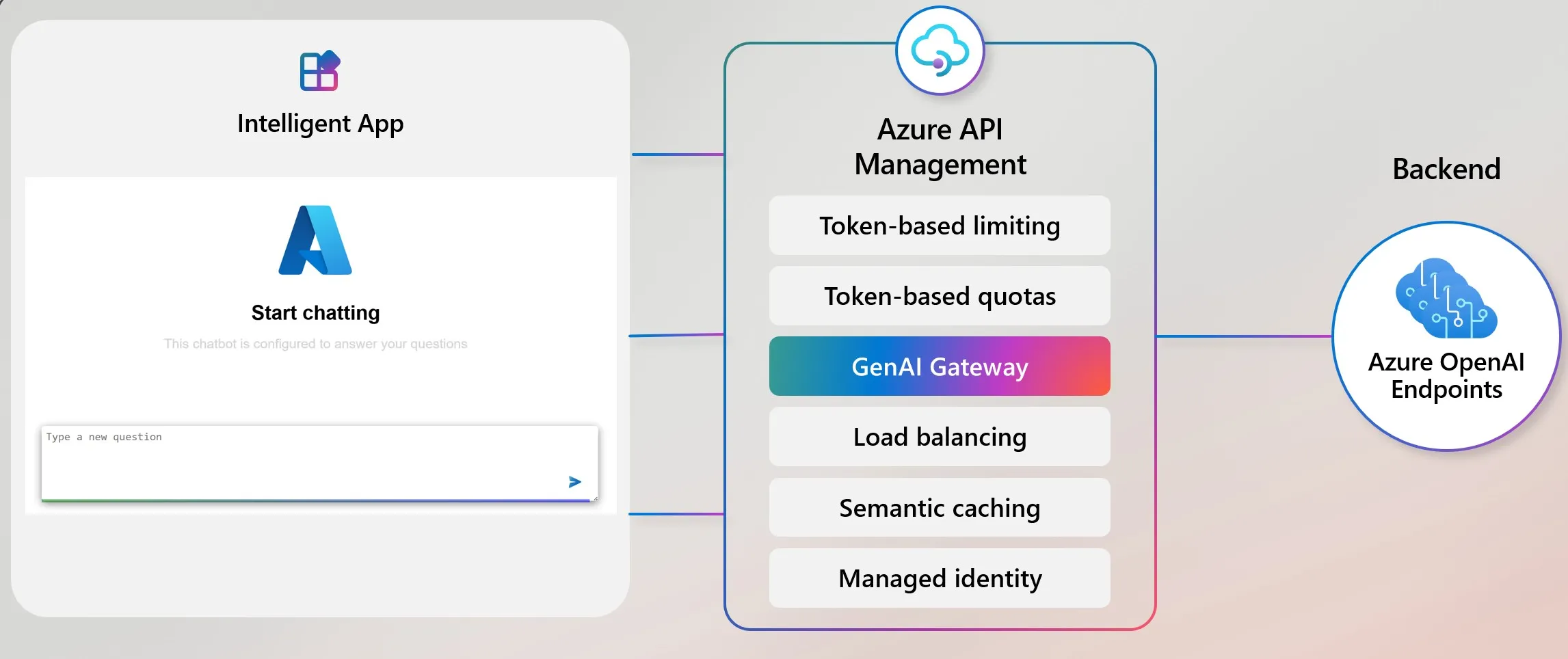
Figure 1: Enterprise GenAI Gateway Pattern (Source: Microsoft Azure Samples)
Network Configuration
- Model endpoints are configured for private access using Private Endpoint+Private DNS. Where required, public network access is disabled so Private Endpoint is the exclusive path.
- Tooling systems (for example, Azure AI Search) use the same private connectivity approach.
- APIM-Internal is deployed in internal VNet mode (or equivalent private-only access pattern), so it is reachable only within controlled networks.
- Egress is restricted so workloads cannot call model endpoints directly. Access is permitted only through approved gateway paths.
“One Rulebook”
This is the governance standard applied to both APIM instances:
- Identity at the gateway (who is calling).
- Request throttling (requests per time window).
- Token governance (tokens per minute and/or token quotas) using APIM
GenAI policies, including
azure-openai-token-limit. - Audit-ready logging with consistent fields and correlation IDs (caller, environment, model/deployment, tool invoked, token usage, latency, backend route).
- Tool allowlisting (agents can call only approved tools, not arbitrary URLs).
- Exceptions are time-boxed with an owner, expiry date, and compensating controls.
The Architect's Checklist
Ready to build a GenAI Gateway? Use this checklist to verify your posture before go-live.
Definition of done: model and tool access is routed through controlled gateway paths with consistent policy and traceability.
Day 1 Scope
External Customer Agents (Phase 1)
Allowed:
- Read-only knowledge and safe lookups (public FAQs, product guidance, status checks with strict scope).
Not Allowed:
- Any internal tools.
- High-risk actions (account changes, payments, entitlements).
Internal Employee Agents (Phase 1)
Allowed:
- Enterprise search and knowledge retrieval.
- CMDB and operational context lookups.
- Low-risk workflow actions (for example, ticket drafts or controlled ticket creation).
Not Allowed (until extra gates exist):
- High-risk write actions without step-up controls (approval and/or human-in-the-loop).
Four Challenging Scenarios
Bot Storm & Cost Spike
A marketing event drove massive traffic. Bots piled in. Token spend threatened to drain the quarterly budget in 48 hours.
Deterministic Throttling
- WAF bot controls at the edge.
- APIM enforced hard token budgets.
- Outcome:
429(Rate Limit) &403(Quota) stops abuse.
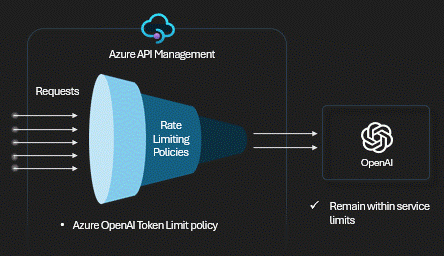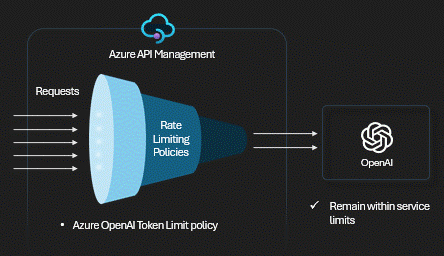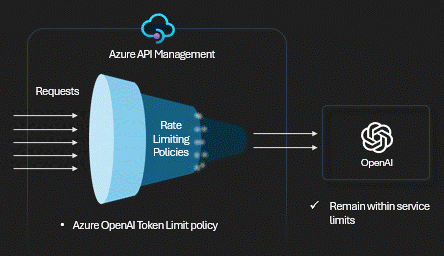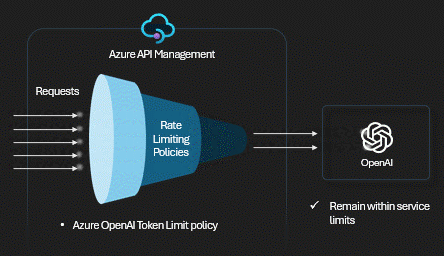
Technical Control: Token Limits
We use the
azure-openai-token-limit policy. It tracks consumption across all
keys. When the bucket is empty,
the gateway returns a 429 Too Many Requests immediately,
saving the backend from overload.
View APIM Policy: Token Rate Limiting
<!-- Enforce token limits per subscription -->
<azure-openai-token-limit
counter-key="@(context.Subscription.Id)"
tokens-per-minute="50000"
estimate-prompt-tokens="true"
remaining-tokens-variable-name="remainingTokens" />Direct Access is like ordering a new pizza every time someone says "I'm hungry" ($300/day). Gateway with Caching is like saying "There's already pizza on the table!" for 60% of requests ($120/day). Drag the slider below to see YOUR savings.
The "Cost of Chaos" Calculator
Imagine calling a world-renowned philosopher for every simple question—it's slow and expensive! Instead, our Gateway Librarian keeps a stack of Sticky Notes for common questions. If we've answered it before, we show the note instantly. The philosopher sleeps, and you save $5.
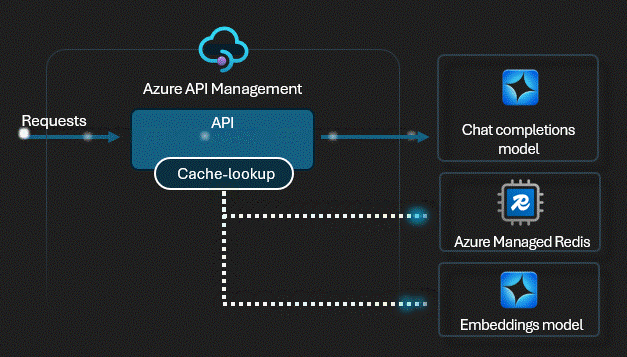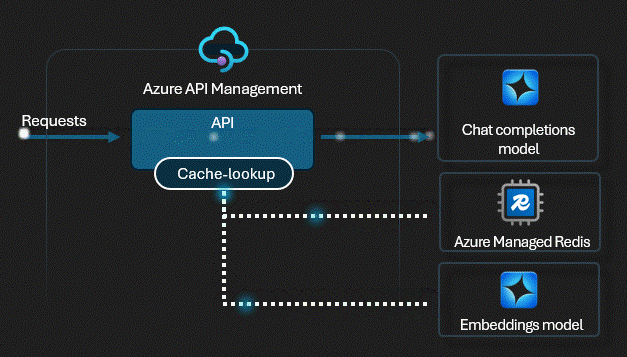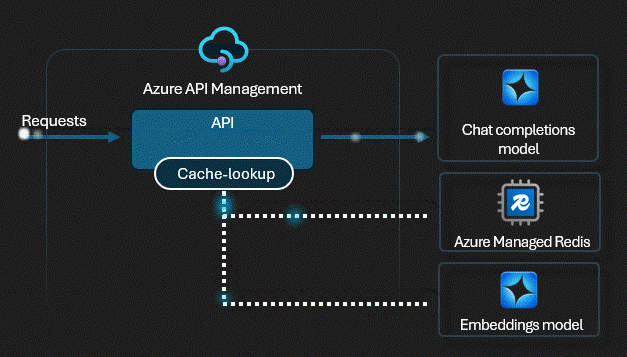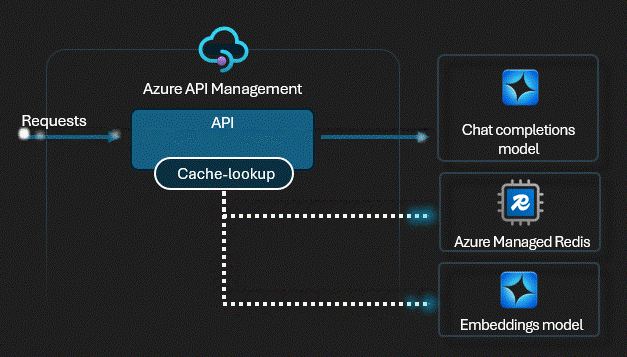
Smart Caching
We enabled Semantic Caching. Unlike simple URL caching, this uses vector similarity. If User A asks "What's the wifi pass?" and later User B asks "Wifi password please?", the gateway detects they are the same intent and serves the cached answer instantly. Zero tokens used.
View APIM Policy: Semantic Caching
<!-- Enable Semantic Caching for Azure OpenAI -->
<azure-openai-semantic-cache-lookup
score-threshold="0.05"
embeddings-backend-id="embeddings-endpoint"
embeddings-deployment-name="text-embedding-3-small" />
<azure-openai-semantic-cache-store duration="3600" />Proof Artifacts: Token usage by consumer, blocked calls, top callers.
The LLM is like a famous celebrity. Some people try to send letters with "Secret Commands" or mean words. The Gateway is the Mail Inspector who opens everything first. If it sees a "Jailbreak" attempt, it shreds the letter instantly. The celebrity never even sees the attack.
Prompt Injection Attack
External users tried "Ignore instructions" prompts to extract internal data or trigger unsafe actions (Jailbreak).
Content Safety Shield
- No Route: External agent has zero path to internal tools.
- Gateway Guard: Pre-flight content scan.
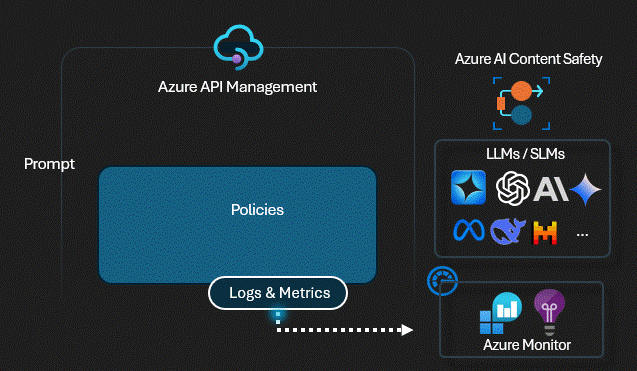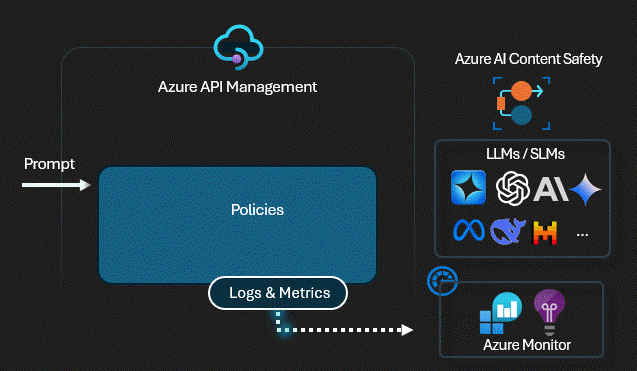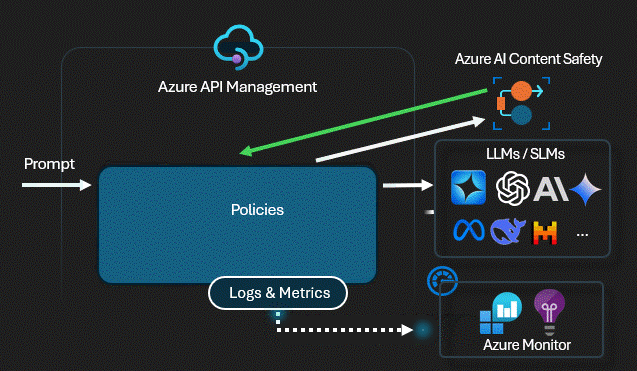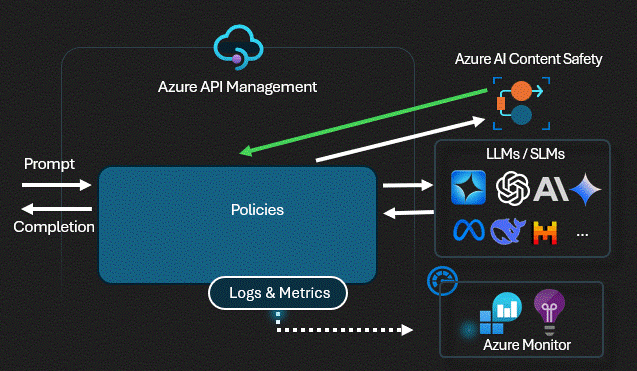
Technical Control: Content Safety
Before any prompt reaches the
LLM,
the Gateway sends it to Azure AI Content Safety using the
validate-content-safety policy. If it
detects Jailbreaks,
Hate Speech,
or Injection patterns,
the request is killed instantly. The LLM never sees the attack.
View APIM Policy: Content Safety
<!-- Sanitize inputs before they hit the LLM -->
<validate-content-safety
backend-id="content-safety-endpoint"
on-error="detach">
<option name="Hate" />
<option name="SelfHarm" />
<option name="Sexual" />
<option name="Violence" />
<option name="Jailbreak" />
</validate-content-safety>Model Degradation
Primary East US 2 model slowed down. Latency spiked +500ms, risking user trust.
Circuit Breaker
- Routing: Traffic shifted to UK South.
- Speed: Transparent to end-users.
Imagine the big game is on, and the city's power grid (Primary Instance) starts to flicker. In milliseconds, the Stadium Backup Generator (Secondary Region) kicks in. The lights stay on, the game continues, and the crowd never even knows there was a power surge.
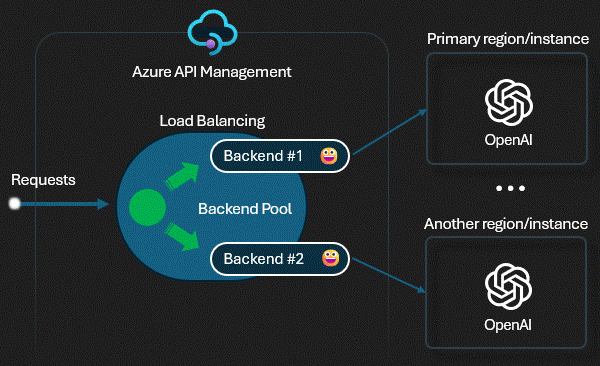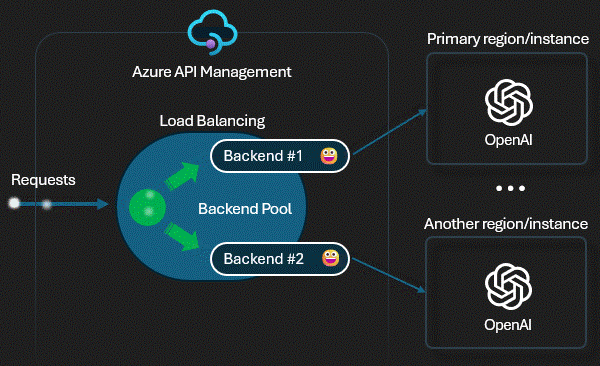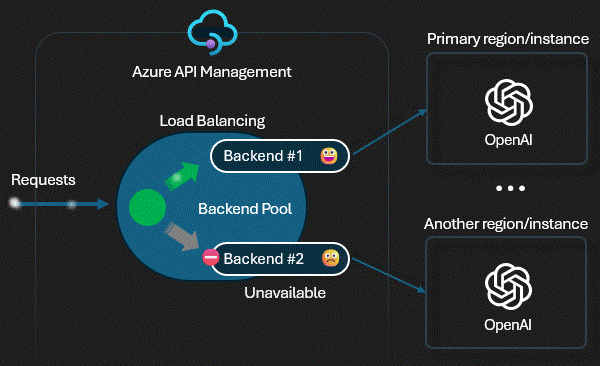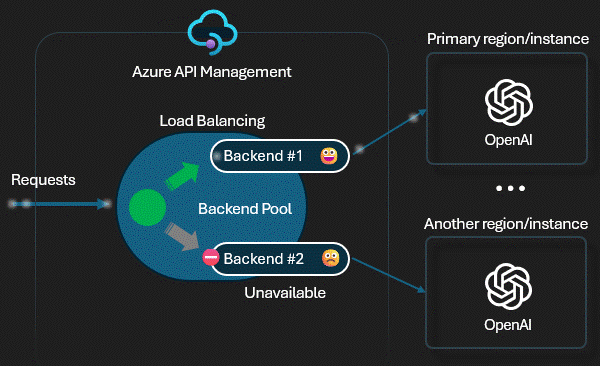
Technical Control: Load Balancing
We use APIM's
Backend Pools (backend-pool policy). If
the primary East US 2 model slows down (high latency) or returns 5xx
errors, the Gateway automatically shifts traffic to the secondary UK
South instance. This "Circuit Breaker"
happens in milliseconds, invisible to the user.
Your family has a rule: "Everyone must have a driver's license with a photo ID." But Grandpa has a 1950s license with no photo—it's valid, but doesn't meet modern standards.
The Compromise: Grandpa can ONLY drive on the private family driveway (APIM-Internal), you install a dashcam in his car (enhanced logging), and you set a deadline: "Grandpa, you have 6 months to get a new license" (time-boxed exception).
He's not blocked from essential trips, he's not on the public highway where he could cause chaos, you're tracking everything, and there's a plan to fix it.
Legacy App (No Auth)
Critical OpS system couldn't adopt new Identity standards. Risk of total blocker.
Private Lane
- Gate: Allowed ONLY via APIM-Internal.
- Audit: Enhanced logging enabled.
Operating Model
Weekly KPIs
- % of model calls routed through gateways (target: 100%)
- Token spend by app/team vs budget
- p95 latency and error rate per agent API
- Number of failovers
- Exception count and burn-down trend
Go-Live Checklist
- [] APIM-External and APIM-Internal deployed and scoped
- [] Model endpoints private (Private Endpoint + private DNS)
- [] Tool services private (Search/DB/Storage)
- [] Gateway identity enforced
- [] Request throttles + token quotas enabled
- [] Token metrics enabled
- [] Tool allowlist implemented
- [] Failover tested
- [] Abuse tests executed
- [] Exceptions process live
Resources
Video Vault (Must Watch)
Expert deep-dives on the patterns used in this architecture.


Read More
Join the Conversation
See what the community is saying about this architecture on LinkedIn: