"The regulator didn't care about the demo. They cared about the data residency."
In the "Demo-Ware" world, AI is easy. You grab an API key, throw some JSON at a public endpoint, and celebrate. But when a multi-billion pound life sciences regulator walks into the room, "easy" is a liability.
The Audit Challenge "Your AI looks great, Upendra," Mr. Compliance said, tapping his pen. "But can you guarantee that not one byte of our patient data ever touches a foreign server? And can you prove that even if your web server is breached, the attacker can't sniff our model traffic?"
I didn't give him a slide deck.
I gave him a 4-subscription Terraform plan.
Proven at Scale This architecture was deployed for a 10,000-person UK life sciences company, processing over 50 million AI requests per month while maintaining full MCSB v2 compliance and zero security incidents.
Want the Complete Terraform Code?
Get the full Infrastructure-as-Code with 5 architecture diagrams, MCSB v2 compliance matrix, and step-by-step deployment guides.
View on GitHub⭐ Star the repo if it helps you build your AI fortress!
The "Private Jet" Pattern (PTU)
Most organizations use Pay-As-You-Go AI. It's like flying commercial—you're at the mercy of the airline's schedule and seat availability. For a regulator, that's not good enough. You need **PTU (Provisioned Throughput Units)**.
PTU is your AI's private jet. It's pre-allocated capacity that stays in one hangar (UK South). You pay for the plane whether it’s in the air or on the ground, but you’re guaranteed a flight. No noisy neighbors. No capacity-exhaustion errors during peak hours.

Figure 0: The "Private Jet" Model - Guaranteed Capacity & Logic Isolation.
The "30/10/10" Capacity Split
But private jets are expensive. To make the CFO smile, we sliced the PTU across three separate deployments. We allocated 30 PTU to Production, 10 PTU to Test, and 10 PTU to Dev on the same OpenAI account. This isolation allows our data scientists to run heavy batch tests during the day without ever impacting the live clinical trials. It's the only way to get "Five Nines" reliability without paying "Five Nines" prices.
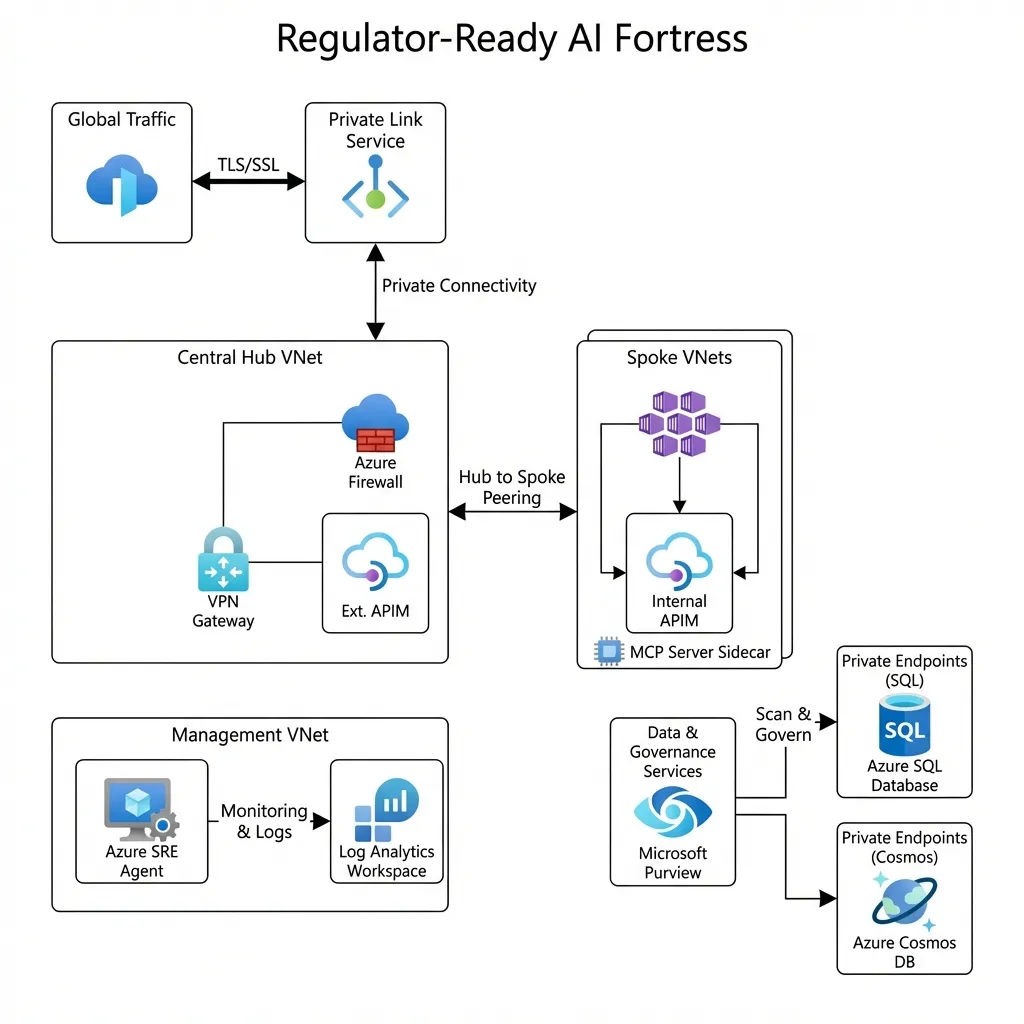
Figure 1: The Executive Summary - Global Traffic to Secure Spoke.
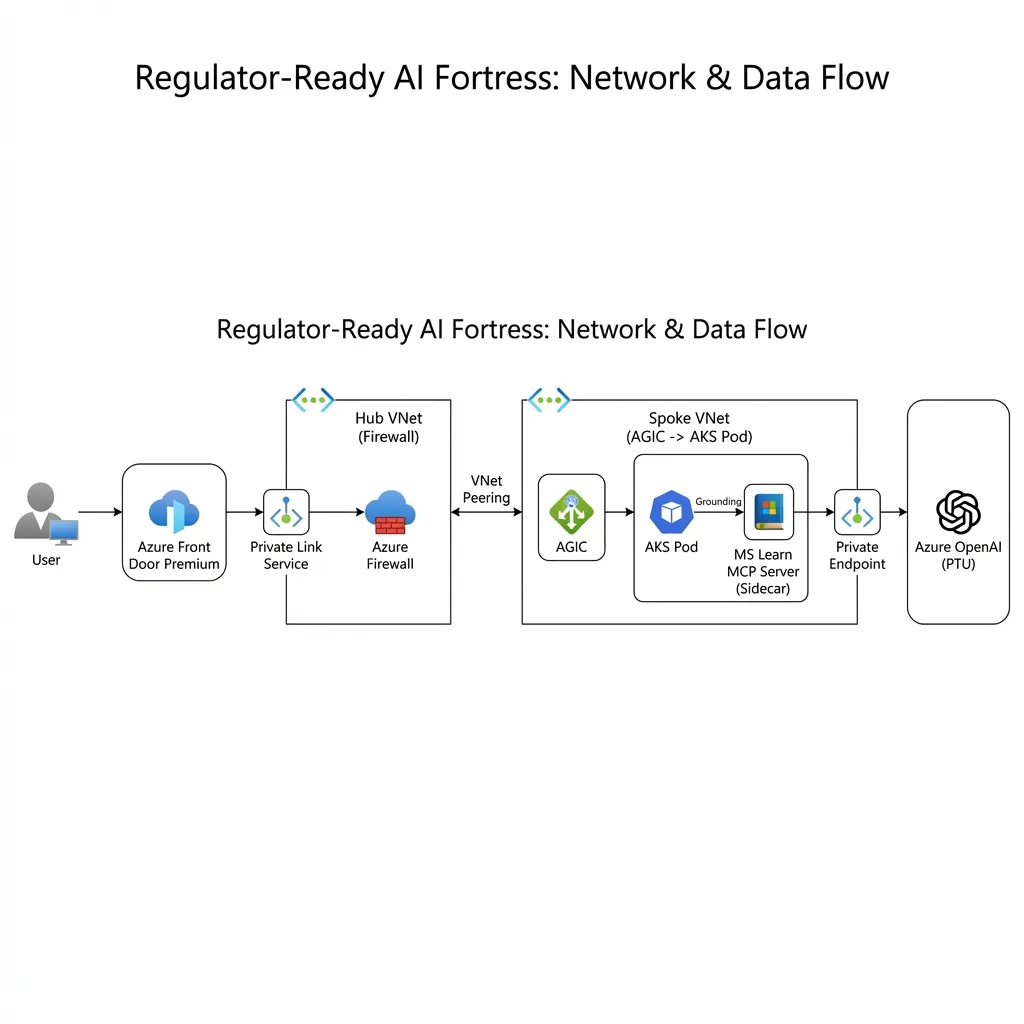
Figure 1.1: The Network Blueprint - Connectivity & Isolation.
Explore the Code: All Terraform modules, network configurations, and APIM policies are available on GitHub with detailed deployment guides.
Killing the Public Endpoint
A "Regulator-Ready" platform has zero public internet ingress to the backend. We achieved this by using **Azure Front Door Premium** with **Private Link Service (PLS)**.
Traffic hits the global edge, goes through a heavy-duty WAF, and then—instead of jumping onto the public internet to find the regional gateway—it slips through an **Invisible Underground Tunnel** directly into the private VNet. The outside world sees nothing.
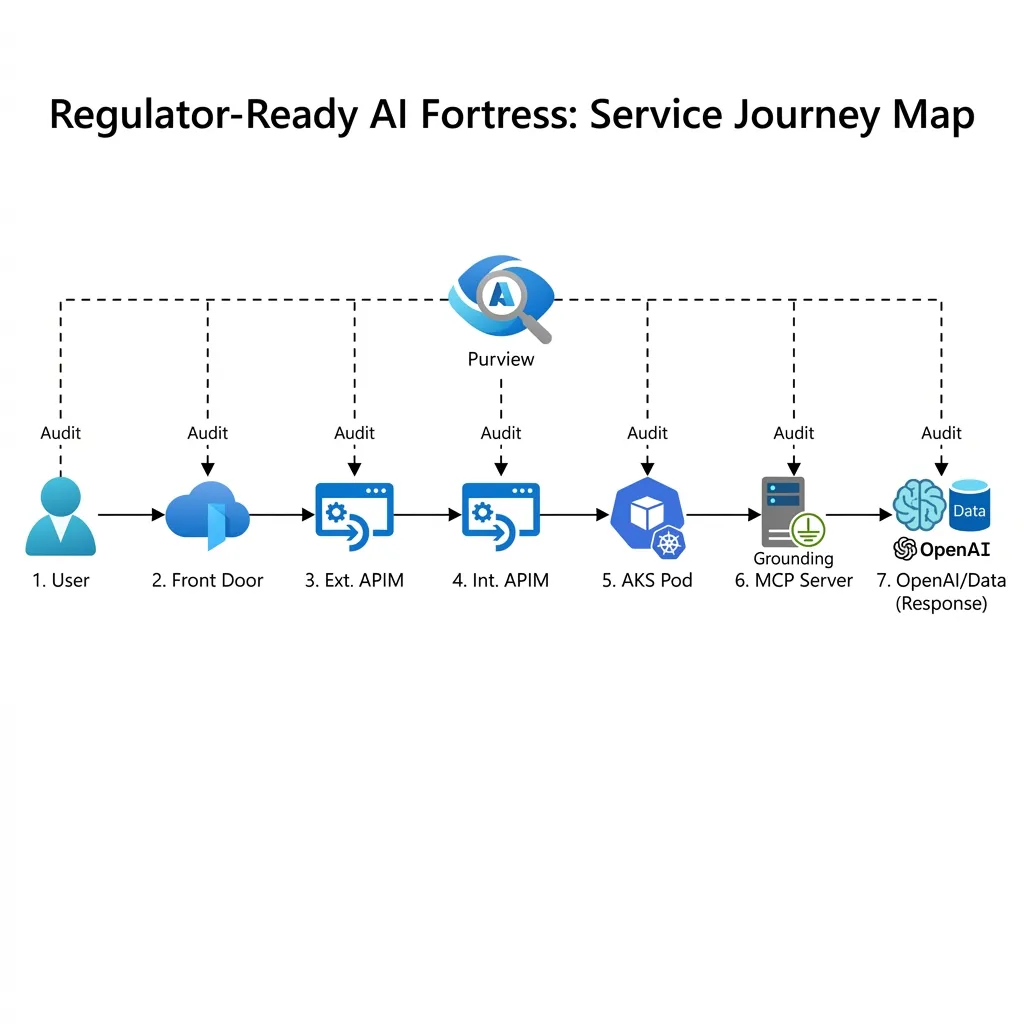
Figure 2: The 6-Step Service Journey.
The "Dual-Gateway" Defense
A regulator asks: "Who watches the watcher?" We answered with two distinct API Management gateways.
Gateway 1: The Bouncer (External)
Sitting behind Front Door, this gateway handles the messy business of the outside world: mTLS authentication, subscription key validation, and basic rate limiting. It stops the DDoS attacks before they even smell the VNet.
Gateway 2: The Brain Surgeon (Internal AI Gateway)
This is where the magic happens. Sitting deep inside the private VNet, this second APIM instance talks only to the AI models. It handles the "Smart" logic:
- Semantic Caching: Why ask GPT-4 the same question twice? Azure Redis Cache stores responses.
- PII Masking: Stripping patient names before the prompt leaves the zone.
- Token Throttling: ensuring no single research team eats the whole PTU pie.
- Grounded Answers (MCP): Routing 'How-to' questions to a dedicated MS Learn MCP Server sidecar, ensuring the AI cites official Microsoft documentation rather than hallucinating.
APIM acts as the **VIP Concierge** for the AI model. It doesn't care about the user; it cares about the tokens. It provides a single "Glass Wall" for auditing every model request, enforcing tiered throttling, and ensuring that no pod overstays its welcome in the PTU first-class cabin.
Why can't the External APIM call OpenAI
directly?
If the External Gateway skipped the Internal Gateway, we would lose our "Brain." We would bypass the
Semantic Cache (Redis), the central PII masking rules, and the global token
throttling.
The Internal APIM is designed to be the only component with network access to the OpenAI
Private
Endpoint, forcing all traffic to pass through our AI safety checks.
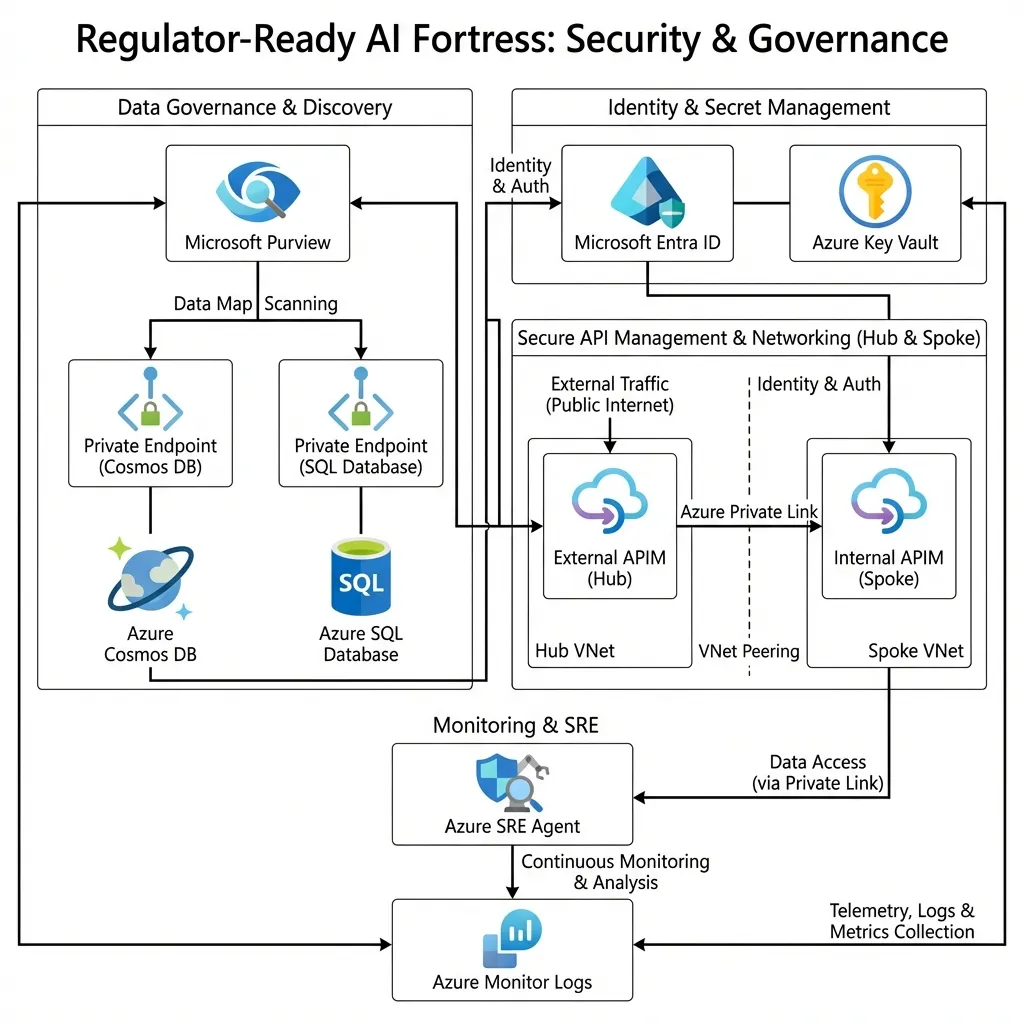
Figure 2.1: The Security Defense in Depth.
The Policy Guardrails (MCSB v2, NIST, PCI-DSS)
A "fortress" isn't just walls; it's the rules of engagement. We used Azure Policy to enforce the compliance standards automatically:
- Microsoft Cloud Security Benchmark v2 (MCSB v2): The foundational security baseline for Azure, covering 420+ controls across Network Security, Identity, Data Protection, and the new AI Security (AS) domain. We assigned the MCSB v2 Azure Policy initiative to all subscriptions for continuous compliance monitoring. This ensures our AI platform meets Microsoft's recommended security posture.
- NIST 800-53: Enforced "Deny Public IP" on all network interfaces and required TLS 1.2+ on all endpoints.
- PCI-DSS: (For payment-adjacent flows) Enforced strict Role-Based Access Control (RBAC) and encryption at rest for all Storage Accounts and SQL Databases.
Beyond blocking bad resources with Azure Policy, we used Microsoft Purview to scan the data inside them. By leveraging Purview's Managed Virtual Network to connect into our Private Endpoints, we automatically classify any PII entering our SQL or Cosmos DB instances without it ever traversing the public internet—making our 'Data Residency' promise a verifiable fact.
Why MCSB v2 for AI Workloads?
Microsoft Cloud Security Benchmark v2 is the evolution of Azure Security Benchmark, adding specific
guidance
for AI workloads. The AS (AI Security) domain includes controls for securing AI
platforms
(AS-1: Private OpenAI), monitoring AI applications (AS-2: APIM logging), and protecting training
data
(AS-3: encrypted storage).
This makes MCSB v2 the most comprehensive framework for regulator-ready AI architectures on Azure.
Results After 6 Months
Since deploying this architecture in production, we've achieved measurable success across security, performance, and cost efficiency:
How we sustained 99.97%: We built and deployed a custom AI SRE Agent (using Azure OpenAI & Logic Apps)—an autonomous watcher that monitors our telemetry. It auto-triages routine alerts (like transient latency spikes) and executes restart runbooks for non-critical pods, freeing our human engineers to focus on architecture, not firefighting.
"The 4-subscription model gave our CISO the confidence to approve AI in production. The audit trail alone saved us 200 hours during our ISO 27001 certification." — Head of IT Security
Ready to Build Your Own?
The complete Terraform infrastructure that powers these results is open-source and production-ready.
Hybrid Identity & Access
Identity is the new perimeter. We didn't create new bespoke credentials for this fortress. We extended the corporate trust:
- The Flow: Users authenticate via their existing **Windows AD** credentials on-premises.
- The Sync: **Entra Connect** synchronizes these identities to **Entra ID** (Azure AD) in the cloud.
- The Gatekeeper: **Conditional Access** policies check the user's device health (Intune) and risk level before granting a token to access the Internal APIM.
What Happens When UK South Goes Down?
environment—we don't pay for the compute while it's sitting idle, but the VNet, the security rules, and the SQL Geo-Replication are already there, waiting for the signal.Note on ACR (Azure Container Registry): The diagram shows ACR Geo-Replication. This ensures our Docker images are automatically synced to the UK West registry. If UK South fails, the standby AKS cluster pulls images locally from UK West, avoiding any cross-region dependency during a crisis.
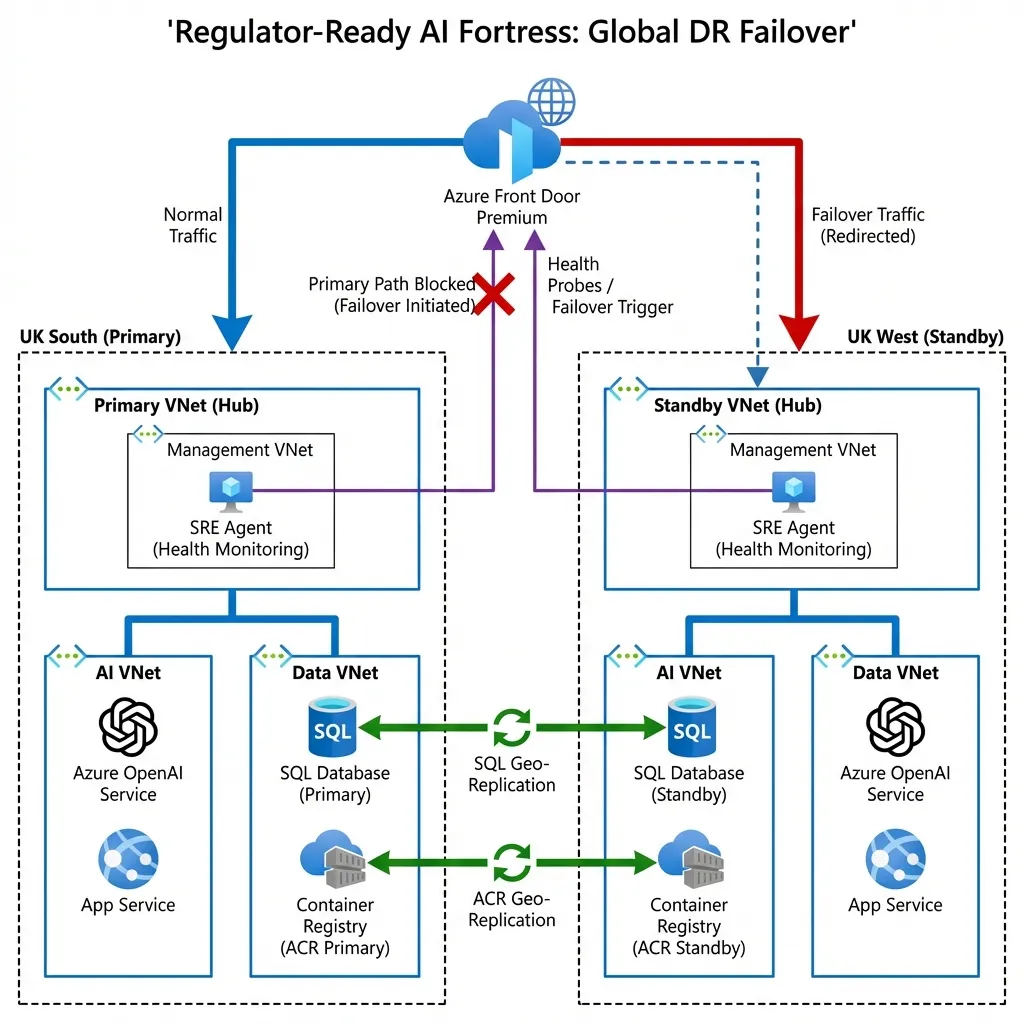
Figure 3: Automatic Global Failover in Action (PaaS Architecture).
Architectural Design Decisions
Every component in this architecture fought for its place. Here is why we chose them:
1. Why App Gateway in Prod/Non-Prod?
Verdict: Essential. It acts as the Ingress Controller (AGIC) for the AKS clusters. While Front Door handles global traffic, it cannot route to specific Kubernetes pods inside a private VNet. App Gateway bridges that gap securely.
2. Why No App Gateway in the Hub?
Verdict: Redundant. The Hub already hosts the External APIM which sits behind Azure Front Door Premium. Front Door provides the WAF and global caching. Adding another App Gateway in the Hub would just add latency and cost without adding value.
3. Why Redis Cache?
Verdict: Critical. We attached Azure Redis Cache Premium to the Internal APIM for Semantic Caching. If two researchers ask the same question, the AI model isn't even touched—Redis answers instantly from the cache. This saves massive amounts of PTU capacity and reduces latency from seconds to milliseconds.
Redis uses an LRU (Least Recently Used) eviction policy, automatically removing old responses when memory is full. Each response is stored with a hash of the prompt as the cache key, with a TTL of 1 hour. This means identical questions get instant answers, while the cache stays fresh.
4. Why GRS Storage?
Verdict: Compliance. We use Geo-Redundant Storage (GRS) to ensure that if UK South disappears, the audit logs and model artifacts exist in UK West. It underpins our "Passive Cold" DR strategy.
5. What about Key Vault?
Verdict: Mandatory. A fortress needs secure key storage. We use Azure Key Vault to manage the TLS certificates for the Application Gateway and APIM custom domains, as well as storing the API keys for any legacy subsystems that haven't migrated to Managed Identity yet.
Lessons Learned: What We'd Do Differently
No architecture survives first contact with production unchanged. Here are the hard-earned lessons that will save you weeks of troubleshooting:
1. The DNS Resolver Nightmare (3 Days Lost)
The Problem: We initially tried to use the Hub Firewall's DNS proxy feature to resolve
privatelink.openai.azure.com. It worked for the Hub VNet but failed spectacularly for the
Spoke
VNets and on-premises VPN users.
The Fix: Deploy a dedicated Azure Private DNS Resolver in the Hub with
inbound and outbound endpoints. Configure conditional forwarding rules for all
privatelink.*
zones. This added £50/month but saved our sanity.
Time Saved: If you do this from day one, you'll avoid the 3-day DNS debugging marathon we endured.
2. Redis Cache Warm-Up (Cold Start Pain)
The Problem: On day one, Redis was empty. Every single AI request was a cache miss, which meant zero performance benefit and confused stakeholders asking "Where's the 98% latency reduction?"
The Fix: We pre-populated the cache with the top 100 most common queries from our test environment. We also adjusted expectations: cache hit rates start at 0% and climb to 70-80% over 2-3 weeks as the cache learns usage patterns.
Lesson: Set realistic expectations. Redis is an investment that pays dividends over time, not instantly.
3. The "4-Subscription Tax" (Operational Overhead)
The Problem: Managing 4 separate Azure subscriptions (Shared Hub, Prod, Non-Prod, DR) created unexpected operational friction. Each subscription needed its own RBAC assignments, budgets, and policy exemptions.
The Fix: We created a Management Group hierarchy to apply policies at scale and used Azure Lighthouse for centralized monitoring across all subscriptions. We also standardized naming conventions religiously.
Lesson: The 4-subscription model is powerful for isolation, but you MUST invest in governance automation (Terraform, Azure Policy, Management Groups) or you'll drown in manual work.
The Engineering Reality Check (No Paper Architects Allowed)
Diagrams are easy. Production is hard. Here are the three "ugly truths" about this architecture that you need to know before you build it:
- The DNS Headache: Getting
privatelink.openai.azure.comto resolve correctly from the Hub Firewall, the Spoke AKS, and the On-Prem VPN simultaneously is the hardest part of this setup. We used a central Azure Private DNS Resolver in the Hub to forward conditional queries. Do not skip this plan. - The "Premium" Tax: This is not a cheap architecture. Azure Front Door Premium and Azure Firewall Premium are required for the IDPS and WAF capabilities. The infrastructure baseline (excluding PTU) costs approximately £1,500-2,000/month (~$1,900-2,500 USD). With 50 PTU allocated, total monthly costs range from £17,000-20,000 (~$21,000-25,000 USD). Security and guaranteed capacity are investments, not features.
- Physics is Real (Latency): The Network Flow (Front Door -> Hub Firewall -> Spoke Gateway -> APIM -> AI) induces an estimated 15-20ms of network latency due to the multi-hop security architecture. This is exactly why the Redis Cache sidecar is non-negotiable—it saves round-trips for repeated queries.
Skip the Manual Steps
Instead of clicking through the Azure Portal, deploy the entire infrastructure with Terraform in ~45 minutes.
View Terraform CodeDeployment Runbook: Start Here
Don't just read about it. Deploy it.
# 1. Clone the Regulator-Ready Repo
git clone https://github.com/appliedailearner/uklifelabsaisolution.git
# 2. Login to Azure
az login
# 3. Apply the Terraform Blueprints
cd infra && terraform init && terraform apply
The Junior Engineer's Glossary
Too many acronyms? Here is your cheat sheet:
-
AGIC:
Application Gateway Ingress Controller. It lets Kubernetes talk directly to the Azure Load Balancer. -
PTU:
Provisioned Throughput Units. Buying "reserved seating" for AI capacity so you never get throttled. - Private
Link:
A secret tunnel that connects Azure services (like SQL) to your VNet so traffic never hits the public internet. - Semantic
Caching:
Storing the "meaning" of a question. If someone asks "Who is CEO?", we answer from Cache instead of paying OpenAI again.
Operationalize Your AI Journey
I help organizations turn stalled cloud initiatives into high-performance execution engines.
Build Your AI Fortress
Get the complete Terraform infrastructure, compliance matrix, deployment guides, and architecture diagrams.
⭐ Join 100+ engineers who have starred this repo