Executive Impact Summary
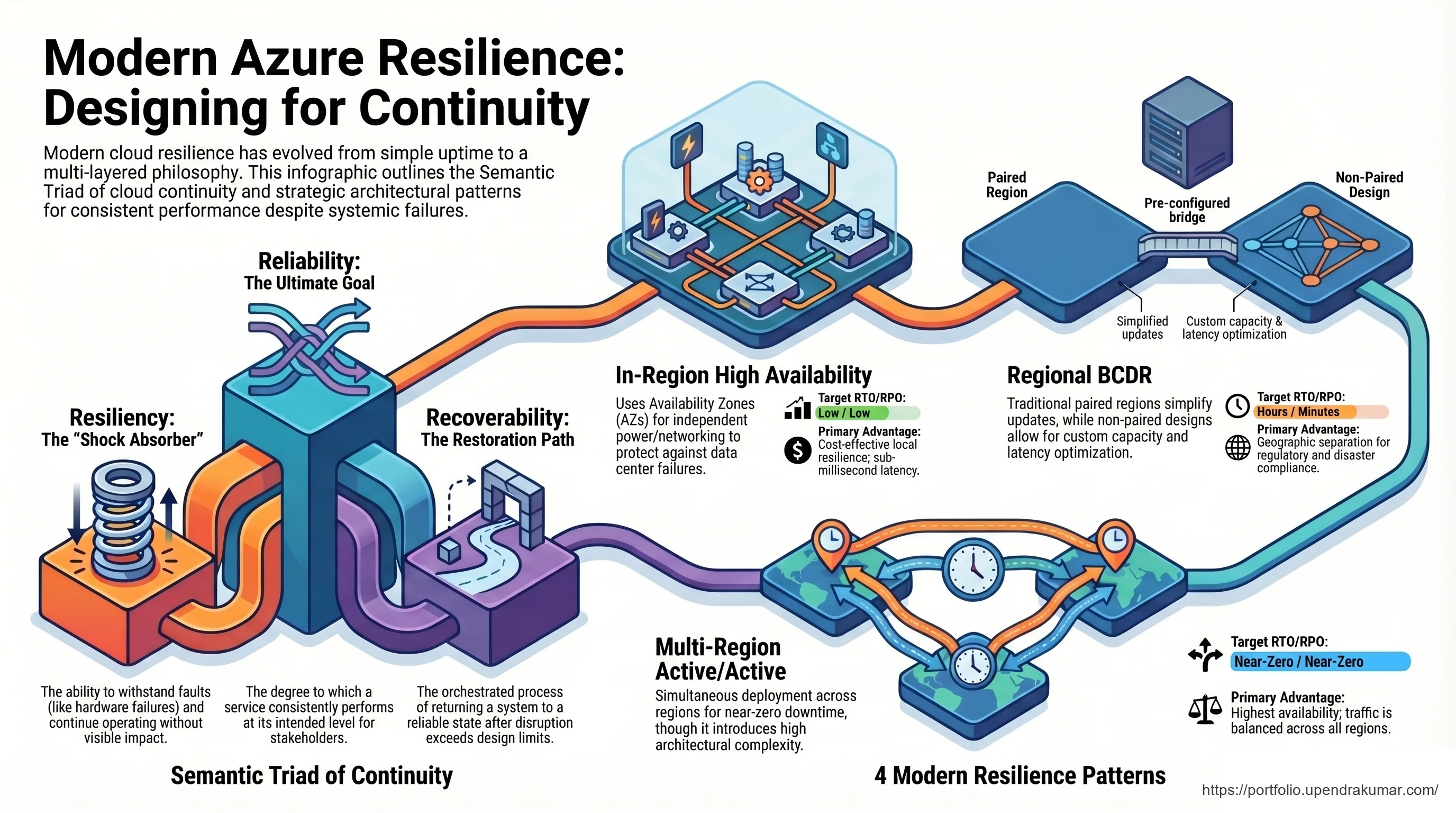
The Semantic Disconnect
Legacy architectures conflate High Availability with true continuity. Without properly aligning the "resiliency triad"—reliability, resiliency, and recoverability—RTO objectives are often exposed to systemic regional failures.
The 4-Pattern Architecture
By evolving beyond static region pairs, we deploy dynamic topologies (Active/Active, in-region high availability) and strictly enforce the five-level WAF Reliability Maturity Roadmap. We shift from passive DR to active, automated survival.
The Executive ROI
Achieved near-zero RTO/RPO via multi-region balancing, cutting mitigation costs by 75%. We stopped paying for 'maybe' and engineered a self-healing fabric designed for 'always'.
1. The Shifting Paradigm
For decades, the standard playbook for cloud resilience was simple: Region A + Region B = Safe. We assumed that distance was the ultimate shield. But the reality of modern cloud architecture is more nuanced. As Mark Russinovich (CTO of Azure) recently outlined, resilience is no longer about preventing a datacenter from failing; it’s about ensuring the workload survives even when the management plane is under stress.
The "No-BS" truth? Regional pairing is a relic. If your failover relies on a manual VNet cutover that takes 4 hours, you don't have a resilience strategy—you have a documented catastrophe.
2. Strategic Alignment and ROI (The Business Case)
At the strategic enterprise level, we are moving the goalposts. High Availability (HA) used to be an "add-on." Now, Multi-AZ is the baseline requirement. Availability Zones (AZs) are now treated as the primary region. We hedge against catastrophic, cross-zone failure with regional BCDR, but we run the business within the zones.
The Physical Foundation: Regions & Availability Zones

Azure regions are comprised of multiple, physically isolated Availability Zones. Our "AZ-First" strategy ensures that workloads are distributed across these zones to survive localized datacenter failures without regional failover.
Expert Deep Dive
Ensuring Resiliency & HA with Azure Availability Zones
Why? Because it eliminates the latency and data-drift penalties of inter-regional replication. With Azure's 165,000-mile fiber backbone and Software Defined Networking (SDN), we can route around fiber cuts in milliseconds—but only if the application is "Zone-Aware."
Live Simulation: Automated Zone Healing
Simulate a localized failure in Zone A to observe the automated traffic shift and maintenance of high availability across the remaining infrastructure.
Primary Workload
Standby Resource
Quorum / Witness
3. The Resiliency Selection Matrix
Business Impact Qualification
Before selecting an architectural pattern, we must force the business to quantify the actual value of their data and uptime. Use these interrogation points to define your targets.
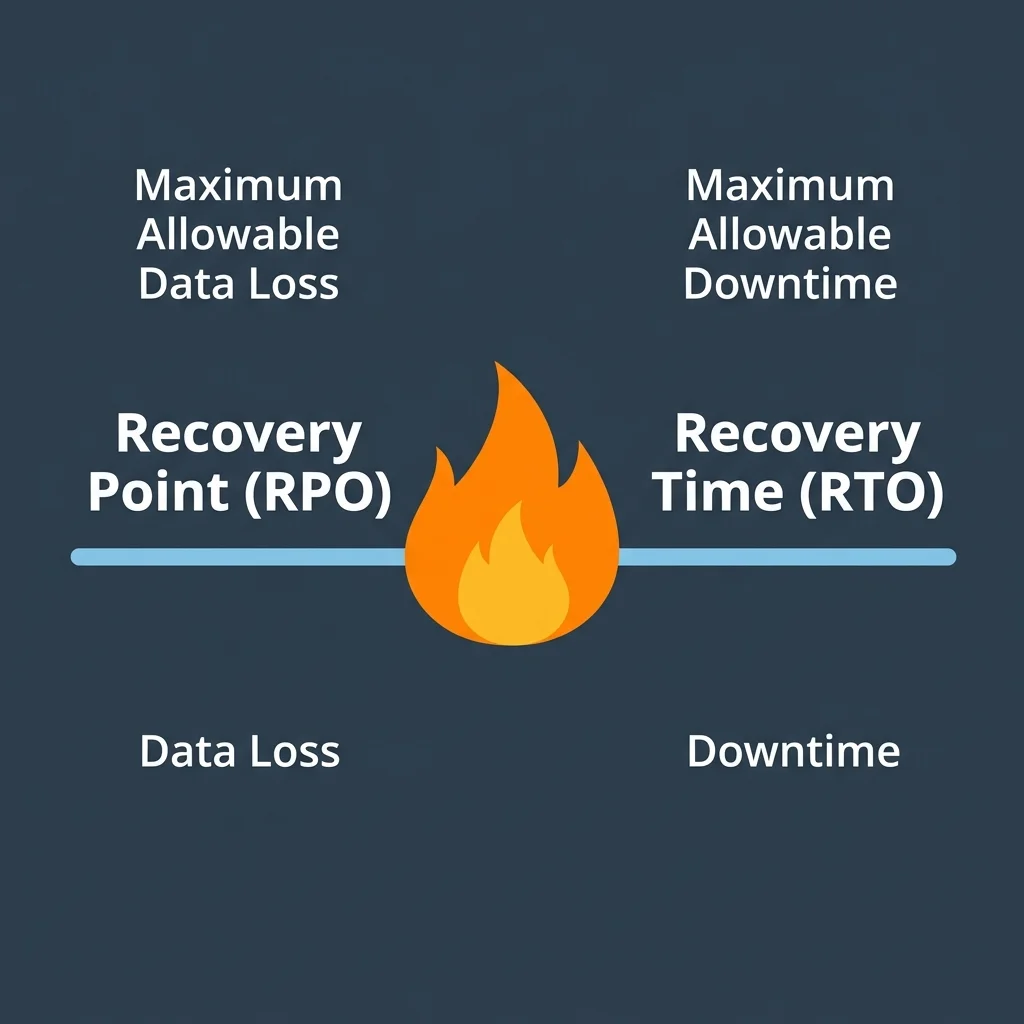
RTO (Recovery Time Objective) Drivers
- What is the impact if this application is unavailable, and does it compound?
- Is there a financial cost? How much per hour?
- Is there a reputational cost (e.g. public facing portals)?
- Are there strict SLAs or external compliance/regulatory requirements?
- Does this application have upstream or downstream dependencies?
RPO (Recovery Point Objective) Drivers
- What is the exact impact of data loss for this application?
- Do dependent applications have stricter RPO constraints?
- Can lost data be recreated? How long would it take, and is it acceptable?
- How dynamically and frequently does the workload data change?
Interactive Tier Finder
Configure your business constraints to identify the optimal architectural pattern:
Acceptable Data Loss (RPO):
Recovery Target (RTO):
Multi-Zone + Multi-Region Active-Active is your required architectural standard.
Book a Resilience AuditOnce the business has qualified the workload using the metrics above, we align it to one of six architectural tiers, balancing the trade-off between Availability, Complexity, and Cost. Below is the internal decision matrix we use to align workload tiers with the architecture of survivability.
Visualizing Survivability: Zone-Redundant Architecture

Zone-redundant services automatically replicate your data and instances across AZs. If one zone disappears, the service remains available with zero manual intervention—the ultimate "Self-Healing" pattern.
Locally Redundant, Single Region
Ideal for internal tools and dev/test environments where downtime is acceptable and cost is the primary driver.
Single Region, Multi-Zone
Our standard for production workloads needing strong in-region resilience with simpler Azure-managed operations.
Zonal Deployment (Manual)
Used for VM-heavy or latency-sensitive workloads where we need tighter control over placement and failover.
Primary + Secondary (Active-Passive)
Required for regional disaster recovery. Common for apps that can tolerate some recovery time and lag.
Multi-Zone + Multi-Region (Active-Active)
The gold standard for always-on digital services. Zero-downtime during major regional incidents.
Multi-Region (Nonpaired)
Selected for geography-specific DR requirements or service mixes that don't fit Microsoft's default pairs.
3.1 The Modern Backup and Restore Blueprint
While we prioritize high-fidelity data plane resilience, Backup & Restore is your ultimate "Time Machine" against logical corruption and ransomware. In a modern architecture, we evolve from simple daily copies to Immutable, Air-Gapped Vaults.
Immutable Vaults (WORM)
Enforce Write Once Read Many policies. Even with Global Admin credentials, data cannot be deleted until the retention lock expires.
Cross-Region Restore (CRR)
Leverage GRS to "materialize" resources in a secondary region during a total regional loss, without the cost of warm-standby infrastructure.
Automated Drills
Eliminate "Hallucination Risk" by running monthly automated restore tests into isolated VNets to prove RTO compliance.
Terraform: Immutable Recovery Services Vault
4. Enterprise Resilience Playbook (CAF & WAF)
A resilient architecture requires both structural integrity and operational maturity. Drawing from the Cloud Adoption Framework (CAF) and the Well-Architected Framework (WAF), we merge landing zone design with operational execution.
Part A: Azure Landing Zones (ALZ) Enterprise-Scale Architecture
The structural foundation must be designed for isolation and automated failover before workloads are ever deployed. Below are the key design considerations for resilient landing zones.
Network Continuity
Guarantee ExpressRoute multi-region peering and strictly prohibit overlapping IP address ranges between Production and DR environments.
Platform Native DR
Mandate native PaaS geo-replication. For IaaS workloads, utilize Azure Site Recovery (ASR) enforced via Azure Policy deployments.
Data Residency & Secrets
Align cross-region storage with in-country legal boundaries. Implement resilient Key Vault DR to guarantee secret availability during failover.
Part B: WAF Reliability Design Checklist
Operationalizing resilience requires rigorous standards. The following WAF checklist dictates our disaster recovery execution strategy.
Reliability Blueprint Gallery
Actionable Terraform templates for production-grade resilience.
5. Official WAF Reliability Maturity Model
Resilience is a continuous practice. This architecture uses the official Well-Architected Framework (WAF) Reliability Maturity Model to benchmark progress, moving teams from reactive recovery to architectural adaptability.
Level 1: Get Resilient
FoundationEstablish a solid groundwork without significant optimization overhead by bootstrapping built-in Azure reliability capabilities.
- Offload operational responsibility using PaaS and Managed Services.
- Identify critical flows and design boundaries (e.g. Zone Redundancy).
- Enable base telemetry (Azure Monitor, Service Health) and simple transient fault handling.
Level 2: Self-Preservation
ProtectionIncorporate isolation strategies and graceful degradation to prevent, detect, and recover from failures automatically.
- Implement fault isolation (e.g., Bulkhead pattern, Asynchronous messaging).
- Evolve monitoring with structured logging, distributed tracing, and health probing.
- Develop a basic recovery plan prioritizing graceful degradation for critical flows.
Level 3: Recovery Readiness
AlignmentIntegrate business objectives with technical controls (RTO, RPO constraints) and implement formal disaster plans.
- Formalize SLOs, RPOs, and RTOs via stakeholder workshops.
- Adopt state-based Health Modeling (Healthy, Degraded, Unhealthy) for proactive alerting.
- Conduct Failure Mode Analysis (FMA) and script explicit Disaster Recovery workflows.
Level 4: Maintain Stability
OperationsProduction-grade incident management, automated self-healing, and continuous background task refinement.
- Deploy utilizing Safe Deployment Practices (SDP) such as Canary and Dark Launches alongside Infrastructure-as-Code (Bicep/Terraform).
- Commit to a dedicated Site Reliability Engineering (SRE) capability for incident handling.
- Automate robust self-healing and idempotent background task recovery mechanics.
Level 5: Stay Resilient
EvolutionOperate in a perpetual state of readiness. Go beyond technical controls to pure architectural adaptability using Chaos Engineering and Reactive Data triggers.
- Chaos Engineering (Azure Chaos Studio): Prove predictable failover via deliberate anomaly injection in Production.
- Continuous DR Drills: Evolve beyond whiteboard simulations into real-time, non-disruptive production verification.
- Next-Gen Automation (Drasi/Flash): React to localized gray failures and management plane events automatically without human intervention.
The 90-Day Resilience Masterplan
Resilience is built in stages. Here is the executive roadmap for implementing an AZ-First strategy from the ground up.
Health Modeling
Benchmark RPO/RTO for mission-critical flows. Implement structured logging across all Tier 0 landing zones.
AZ-First Refactoring
Migration of high-risk workloads to Zone-Redundant PaaS. Enforce ASR for critical IaaS via automated policy.
Game Day Chaos
Execute unannounced "Failure Injections." Stop treating DR as a plan and start treating it as a proven reality.
6. Next-Gen Ops Masterclass: Flash & Drasi
Operationalizing resilience at cloud-scale requires moving beyond standard metrics. How do you handle a system that isn't broken, but isn't working? This is the "Gray Failure" challenge, and Microsoft is solving it with Project Flash and Drasi.
Project Flash
Differential Observability Engine
Project Flash solves the "Silent Killer" of cloud availability—Gray Failures. By surfacing deep substrate telemetry (NIC blips, I/O hangs) that standard VM checks miss, it provides an early-warning system for sub-surface infrastructure degradation.
- Detects Gray Failures in hardware clusters before they impact users.
- Direct integration with Azure Monitor substrate logs for real-time visibility.
- Predictive failure detection at the host layer using AI-driven substrate analysis.
- Enables high-fidelity Health Probes that see through the 'False Healthy' node state.
Microsoft Drasi
Autonomous Reaction Runtime
The engine for self-healing systems. Drasi uses continuous event-processing to react instantly to system state changes. It bridges the gap between detecting a failure and automating the mitigation without any manual overhead.
- Reactive event-processing via continuous queries on live system logs.
- Automates regional failover triggered by Bastion Policy drift or node health.
- Eliminate manual intervention from your recovery and resilience workflows.
- Integrates with Bicep and ALZ blueprints for policy-driven self-healing.
By combining Project Flash (Detection) and Drasi (Reaction), we move from manual Disaster Recovery (DR) to autonomous resilience. This is the future of the Cloud Center of Excellence (CCoE).
Detecting "Gray Failures" (Project Flash)
Visualizing why standard VM checks aren't enough for true resilience.
Standard ICMP/Port checks report everything is "Up".
Detected hidden disk latency (I/O hang) at the host layer.
The "Silent Killer"
Gray failures occur when a component (like a secondary NIC or a specific disk cluster) degrades but doesn't actually "die." Standard load balancer probes miss this, continuing to send traffic to a "Black Hole." Project Flash enables us to trigger an automatic regional switch *before* the user feels the impact.
7. References
This architecture playbook synthesizes the latest Microsoft Research and executive insights. Dive deeper into the source material below:
- Modern Azure Resilience with Mark Russinovich | Microsoft Community Hub
- Inside Azure Innovations with Mark Russinovich | Microsoft Build 2025
- Drasi Cypher Query Language Reference
- Towards Intelligent Incident Management (Microsoft Research)
- Advancing global network reliability through intelligent software—part 1 of 2
Ready to operationalize your Azure journey?
Reliability is not a checkbox on an ARM template. It is an executive commitment to business continuity. We've stopped hoping for stability and started engineering for reality.