Mr. Technical Consultant opened the Agent Dashboard for UKLifeLabs. Yesterday, the demo was clean. Today, one graph was not. Token spend was rising, fast.
Mr. Project Manager pinged: "Plan by Friday. What are we hosting on. AKS or something simpler. One answer."
Mr. Cloud Engineer replied: "Pick the platform. I build today."
Mr. Cloud Architect added: "Landing zone first. Private endpoints, DNS, egress, no shortcuts."
Then Mr. Customer asked the only question that matters: "If this goes viral, do we stay in control, or do we burn money and trust?"
Mr. Technical Consultant knew the trap. Teams pick compute by habit. AI punishes that.
So he wrote one line on the whiteboard:
Compute is not where you run containers. Compute is how you control cost, scale, and blast radius.
The Cast

Architecture, standards, trade-offs.

Build, automation, operations.

Identity, data controls, audit.
Delivery strategy, Operating models, Scale-ready roadmaps.

Risk acceptance & operating model.

Decisions, RACI, milestones.
Imagine you're at a restaurant. The menu has three options: Full Kitchen Service (AKS), Food Truck (ACA), and Microwave Meal (ACI). Each serves different needs.
If you order the Full Kitchen for a simple sandwich, you're paying for chefs you don't need. If you order the Microwave for a wedding feast, you'll fail. The decision tree is your menu guide—it helps you order what you actually need, not what sounds impressive.
The Decision Tree
START
|
|-- Do you need Kubernetes-only features?
| (service mesh, complex scheduling, multi-tenant cluster governance,
| large dedicated GPU pools, strict node-level control)
| |-- YES --> AKS
| |-- NO --> continue
|
|-- Is traffic bursty or unpredictable?
| |-- YES --> Azure Container Apps (ACA)
| |-- NO --> continue
|
|-- Is it a simple "run and exit" CPU job?
| |-- YES --> ACI (CPU only)
| |-- NO --> ACA by default
Thresholds That Stop Debates
- If you need sub-second latency and high sustained throughput and you have a platform team, AKS is justified.
- If you have bursts, idle periods, or uncertain demand, ACA is usually the right default.
- If it is batch + CPU and you can "run and exit", ACI is fine.
- If it is GPU, do not use ACI. Do ACA serverless GPU or AKS GPU pools.
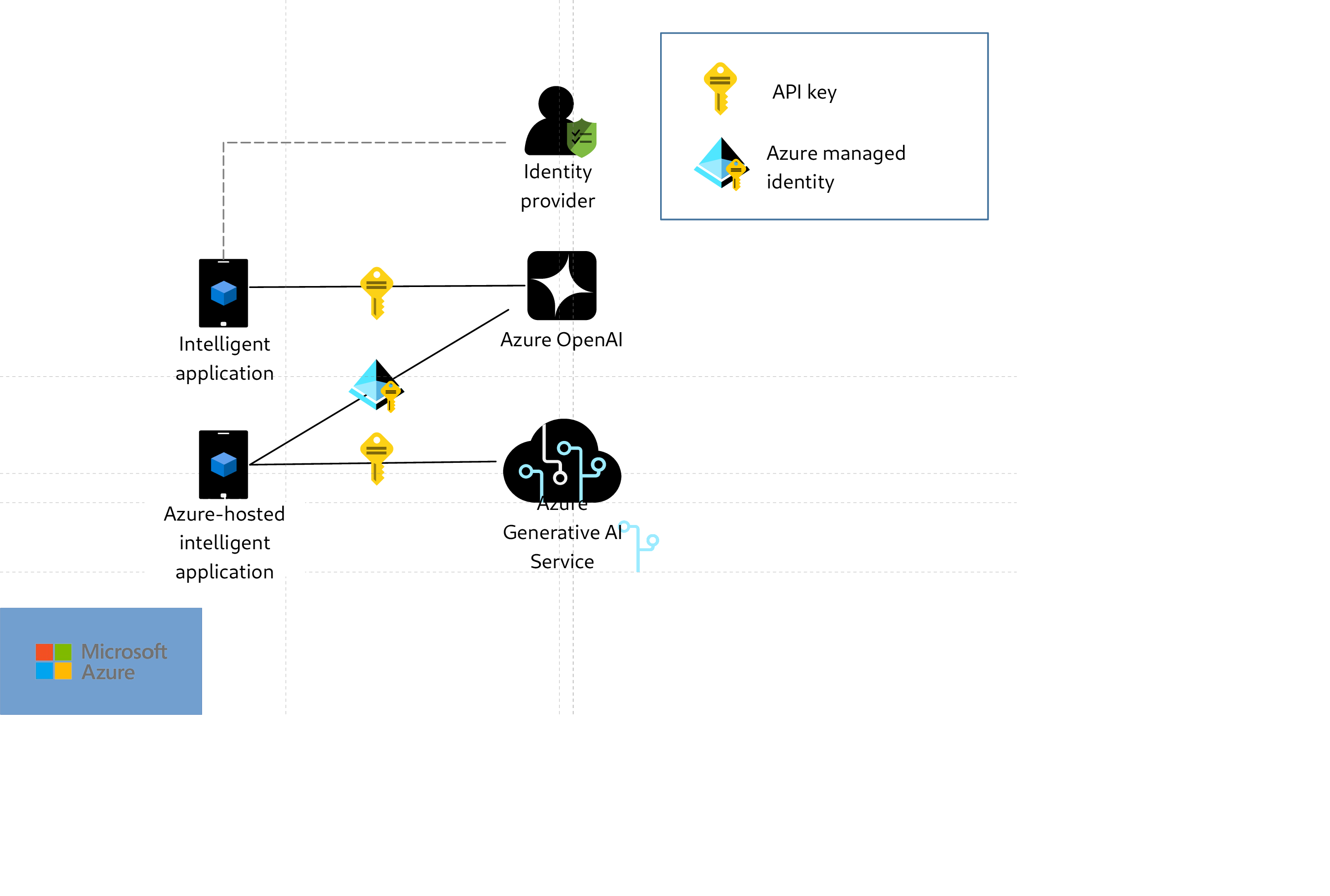
Your AI models are like a VIP nightclub. Without a bouncer (APIM), anyone can walk in, order unlimited drinks (tokens), and trash the place (cost spike).
The bouncer checks IDs (JWT validation), enforces drink limits (quotas), and keeps a guest list (audit logs). No bouncer = chaos. No APIM = uncontrolled spend pipe.
The Non-Negotiable Rulebook
Mr. Customer did not care about AKS vs ACA. He cared about control.
So Mr. Technical Consultant drew this:
Clients/Apps
|
v
APIM (One Rulebook)
- Entra ID auth (JWT validation)
- Token quota + rate limits
- Tool allowlist (only approved downstream APIs)
- Audit logs + correlation IDs
|
v
Compute (ACA/AKS) -> Model + Data (prefer Private Endpoints)
If your apps call model endpoints directly, you do not have an AI platform. You have an uncontrolled spend pipe.
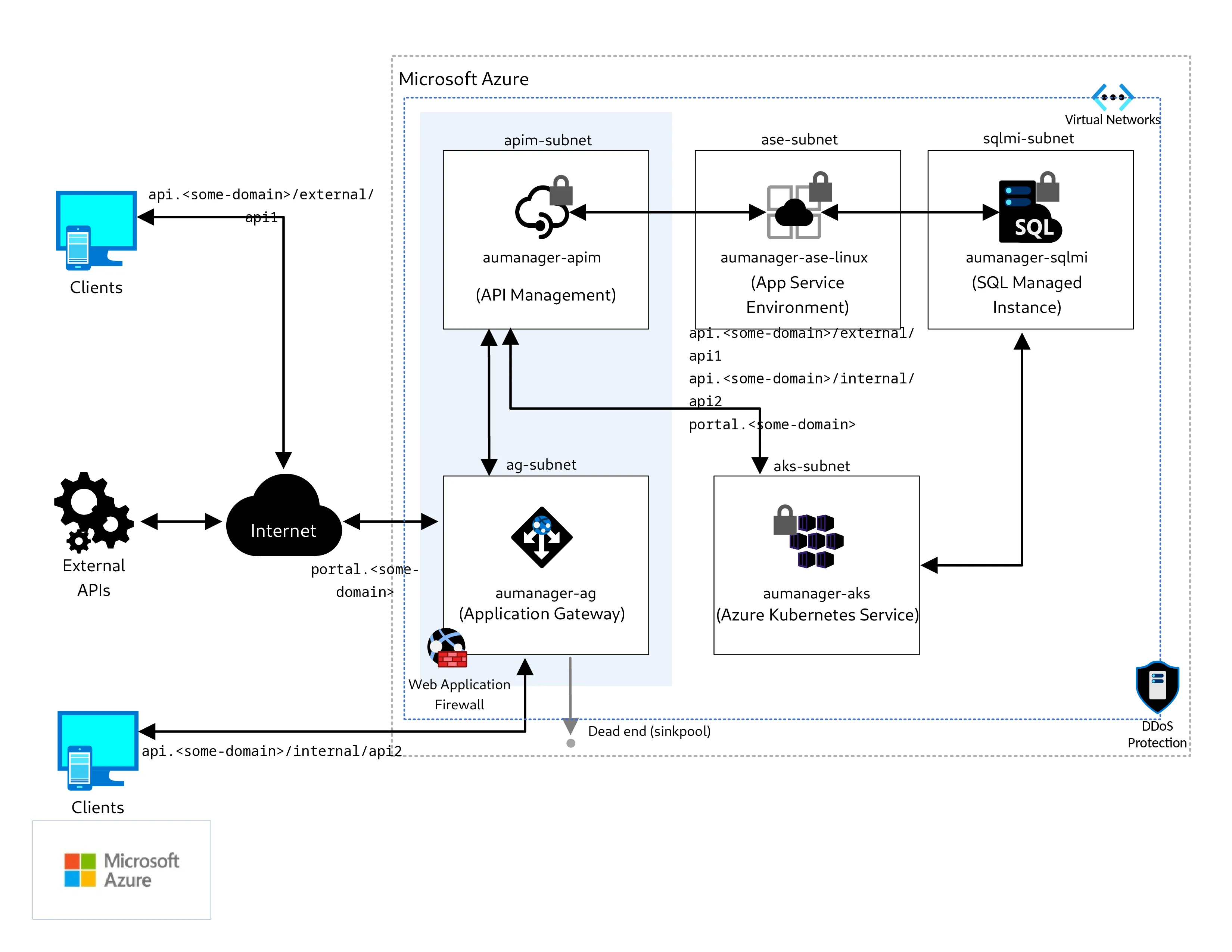
Before Scenarios: One APIM Trap to Avoid
People say "APIM internal" without saying what tier and what networking model.
Add this paragraph to prevent wrong builds:
- If you need a private-only gateway for consumers, you need the APIM internal VNet mode pattern (classic injected networking).
- If you use v2 tiers with outbound VNet integration, treat it as "private to backend", not "private to consumers".
- Do not assume Private Endpoint magically makes APIM "internal". Read the APIM networking limitations first.
This single clarification prevents weeks of rework.
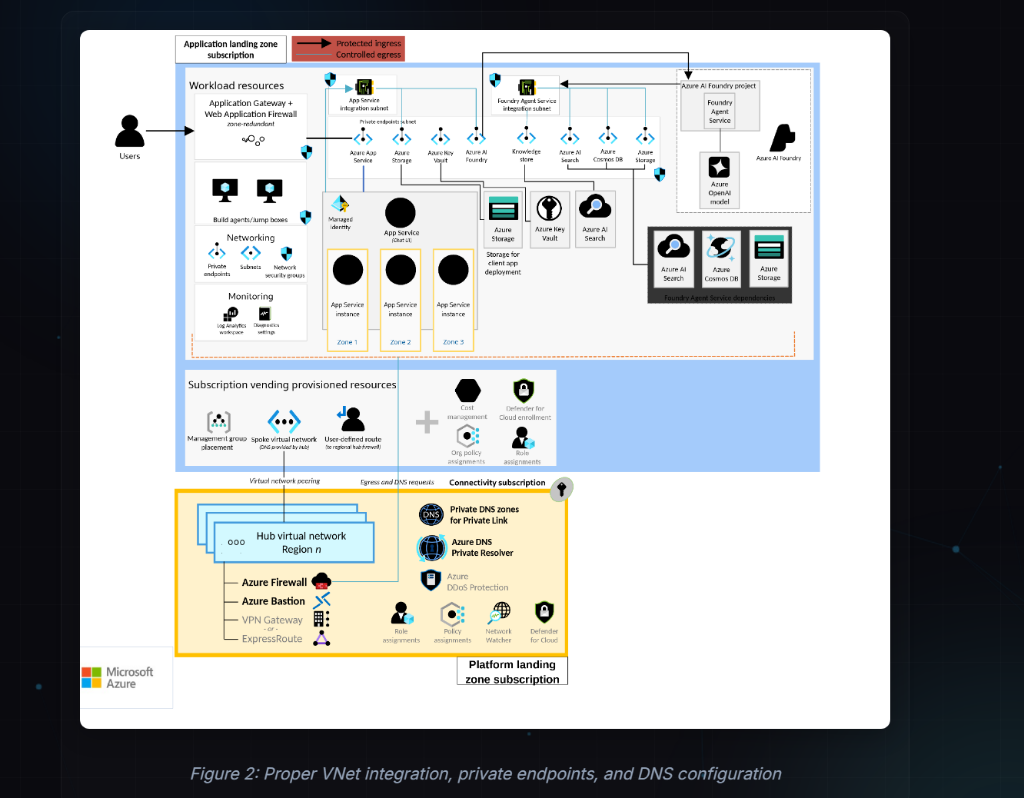
Five Scenarios. Five Reference Architectures.
Each scenario uses the same template so readers can act.
Scenario 1: Internal-Only Agents (Regulated Enterprise)
When: Employee copilots, internal knowledge agents, regulated data.
Non-negotiable constraints:
- Private-only entry
- Private endpoints for model and data
- Egress controlled
Bill of materials:
- APIM internal pattern (private gateway)
- ACA in VNet-integrated environment
- Azure OpenAI with Private Endpoint + Private DNS
- Key Vault for secrets
- Central logging (App Insights + SIEM)
Critical policies:
validate-jwtorvalidate-azure-ad-token- Token quota policy at APIM
- Tool allowlisting at APIM
What breaks first (plan for it):
- DNS mistakes on Private Endpoints
- Outbound egress not matching dependency needs
- "Temporary allow" rules that become permanent
90-minute lab outcome: A private agent API in ACA, fronted by APIM, calling a model endpoint through Private Link.
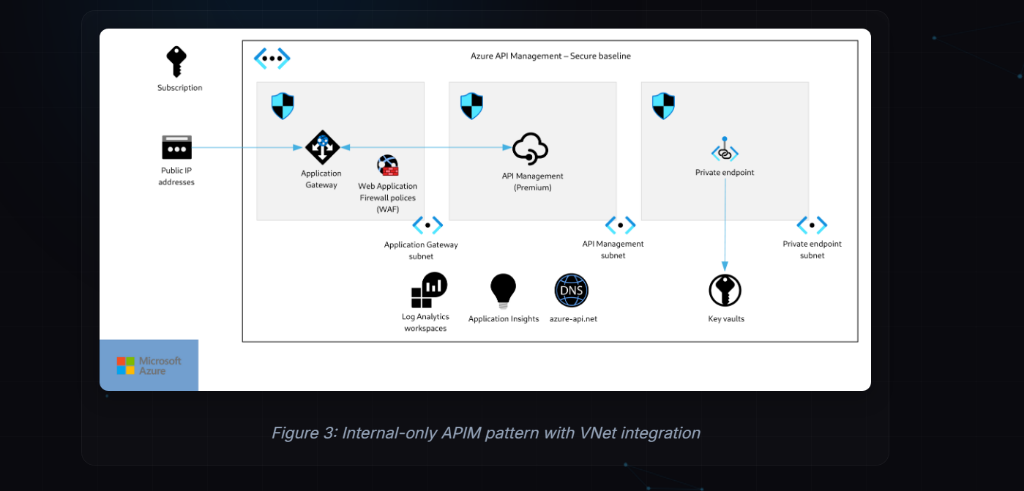
Case Study: UKLifeLabs Picks the Right Home for Agentic Workloads
Mr. Project Manager asked, "We need a pilot by Friday. Does it go on the new AKS cluster?"
Mr. Cloud Engineer sighed. "The cluster isn't hardened for external tools yet."
Mr. Cloud Architect intervened. "The workload is bursty. The SRE team is booked."
Mr. Customer just wanted to know, "Can I see the bill per department?"
Mr. Technical Consultant smiled. "We don't need the cluster. We need a container."
Context
UKLifeLabs needed an internal research agent to query sensitive databases and summarize results.
Constraints
- Internal-only access in a regulated environment
- Bursty and unpredictable demand
- Tool calling to internal APIs and systems
- Scale-to-zero is desired for non-critical components
- No GPU requirement for Phase 1
- AKS is allowed only if Kubernetes-only requirements appear AND there is an SRE operating model
Decision
Azure Container Apps (ACA)
Architecture
- Agent Orchestrator: ACA (consumption profile) for scale-to-zero
- Background Jobs: ACA Jobs for index/embedding refresh and scheduled syncs
- Gateway: APIM (internal) acting as the policy gate for auth, quotas, and audit
- Security: Managed Identity for service-to-service auth; Key Vault for secrets
- Networking: Private networking end-to-end (Private Endpoints + Private DNS); deny-by-default egress
- Observability: Central logging with correlation IDs and redaction for sensitive data
Why not AKS in Phase 1?
- No need for complex custom scheduling or service mesh
- Traffic volume didn't justify dedicated node pools
- No dedicated SRE team available to manage cluster lifecycle
Outcome
- Speed: Deployed in days, not weeks
- Cost: Zero compute cost during nights and weekends
- Governance: Full audit trail and security compliance from Day 1
Mapping to the Decision Tree
Bursty traffic + No GPUs + No K8s-specific control needs = ACA is the correct default.
Scenario 2: Internet-Facing Customer AI (Public Entry, Private Model/Data)
When: Customer chat, partner agent APIs, public portals.
Non-negotiable constraints:
- WAF at the edge
- Hard throttling
- Model + data kept private
Bill of materials:
- WAF (App Gateway WAF or your edge standard)
- APIM as the only public API surface
- ACA for runtime
- Private endpoints to model and data
Critical policies:
- Token quota policy is mandatory
- Bot/abuse throttling at gateway
- Request size limits and payload validation
What breaks first:
- Public endpoints accidentally left enabled on model/data
- Missing per-client quotas, one tenant eats the whole budget
- No audit trail when something goes wrong
90-minute lab outcome: Public endpoint protected by WAF and APIM, backend is private.
ACA is like a food truck—shows up when there's demand, disappears when it's quiet, you don't manage the kitchen. Perfect for bursty traffic.
AKS is like owning a full restaurant—you control everything (the menu, the chefs, the schedule), but you're paying rent even when it's empty, and you need a chef on-call 24/7. Only worth it if you're serving hundreds of customers daily.
Scenario 3: Hybrid Agents (Azure Runtime + On-Prem Tools)
When: Agent must call on-prem systems (CMDB, ITSM, legacy APIs).
Non-negotiable constraints:
- ER/VPN required
- One policy surface for both cloud and on-prem calls
Bill of materials:
- APIM in a controlled network path to on-prem
- ACA runtime in same network boundary
- Tool APIs behind allowlisted routes
- Central observability
What breaks first:
- Asymmetric routing between cloud and on-prem
- Firewall ownership confusion during cutover
- Latency to on-prem tools causing agent timeouts
90-minute lab outcome: An agent that calls one on-prem API and one Azure API, both governed by the same APIM rulebook.
Scenario 4: GPU Skills Without Becoming an AKS Platform Team
When: Vision, heavy embeddings, GPU bursts, custom inference.
Non-negotiable constraints:
- GPU needed for specific skills
- You want scale-to-zero economics
Bill of materials:
- APIM front door with quotas
- ACA serverless GPU workers for GPU skills
- Premium container registry and small images to reduce cold start
- Private endpoints where required
What breaks first:
- Image size and cold start
- GPU quotas in region
- Long-running requests without timeouts and retries
90-minute lab outcome: A GPU "skill endpoint" behind APIM, autoscaling based on demand.
Your model is a celebrity living in a gated community (Azure). Public internet is the paparazzi-filled street.
A Private Endpoint is the secret underground tunnel—only authorized people (your apps) can use it, and no one on the street even knows it exists. No photos, no leaks, no unauthorized access.
Scenario 5: Batch Pipelines and Offline Jobs
When: Backfills, re-embedding runs, nightly summarization.
Non-negotiable constraints:
- Non-interactive
- Cost optimized
- Run and exit
Bill of materials:
- ACI for CPU batch tasks, or ACA jobs/worker pattern for event-driven runs
- Storage for artifacts
- Central logging
What breaks first:
- Lack of idempotency (reruns duplicate data)
- No run metadata (can't prove what happened)
- Hidden dependency on interactive services
90-minute lab outcome: A job that runs on a schedule, logs output, and exits cleanly.
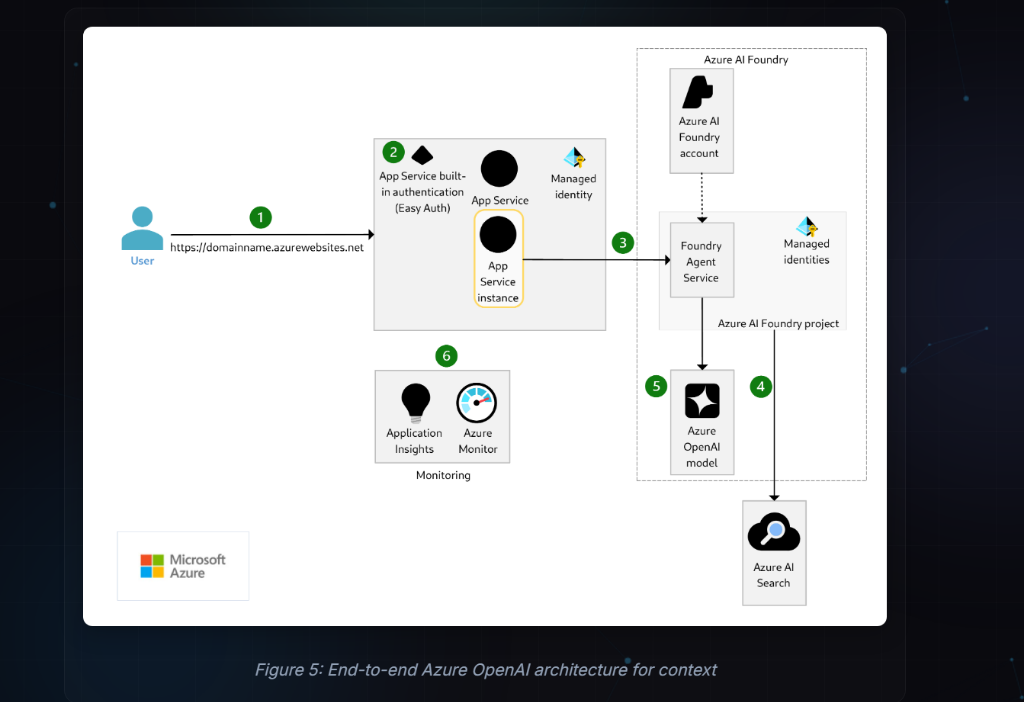
The Moment It Clicked
Mr. Project Manager asked, "What do we tell the client?"
Mr. Technical Consultant wrote the final decision:
- Default runtime: Azure Container Apps
- Default enforcement: APIM rulebook (identity + quotas + audit)
- AKS only when a real Kubernetes-only need exists
- ACI only for simple CPU run-and-exit jobs
Mr. Cloud Architect nodded. "Now I can lock guardrails."
Mr. Cloud Engineer nodded. "Now I can build without rework."
Mr. Customer nodded. "Now I can trust the rollout."
Practical Checklist
- Put APIM in front of every model call and tool API.
- Use Entra ID at the gateway. Do not distribute model keys.
- Enforce token quotas and rate limits per client.
- Emit token metrics and correlate requests end-to-end.
- Use ACA unless you have a proven AKS platform requirement.
- Keep model and data private where required. Get Private DNS right.
- Treat DNS, egress, and quotas as production features, not "later".
Download the Implementation Toolkit
Get the complete implementation package including Terraform templates, APIM policies, and architecture diagrams:
Download AI Hosting Toolkit (v2.0)What's included in v2.0:
- Terraform Templates (VNet + ACA + OpenAI)
- CFO-Ready Cost Calculator (.csv)
- Go-Live Security Checklist (.md)
- Full Architecture Icons & Labs List
- 4 production-ready APIM policy XMLs
- 5 architecture diagrams (PNG + SVG)
- Comprehensive README with deployment guide
- Cost optimization tips and troubleshooting
ZIP file (~3 MB) - Free download, no registration required
Resource Vault (Curated, High Signal)
Start Here (3 Links)
- ACA scaling (KEDA-backed scale rules)
- APIM JWT validation policy (identity at the gateway)
- Limit Azure OpenAI token usage in APIM
Build Labs (6 Links)
- AI-Gateway sample (APIM policy patterns for AI)
- GenAI gateway with APIM
- APIM + Azure OpenAI reference implementation
- Enterprise logging for OpenAI usage
- RAG reference app (Azure AI Search + Azure OpenAI)
- Smart load balancing policy pattern (archived, still useful to learn)
Watch



One-Line Takeaway
If you pick compute without constraints and ship agents without a gateway rulebook, you do not have an AI platform. You have a cost leak.
Unblock your cloud strategy. Start shipping.
Contact Me View the Toolkit